Predicting emergency admissions in Scotland
Background
SPARRA (Scottish Patients At Risk of Readmission and Admission) is a risk prediction model used across Scotland to identify individuals at a high risk of requiring urgent hospital care within the next year. The model was originally developed by Public Health Scotland (PHS) and SPARRA scores are calculated monthly for approximately 80% of Scottish residents.
Individual-level SPARRA scores can be used by medical professionals to plan anticipatory interventions for the patients under their care. At an aggregate level, SPARRA scores may also be used to estimate future demand, supporting planning and resource allocation.
More information about SPARRA and its use cases is provided by PHS here.
SPARRAv4
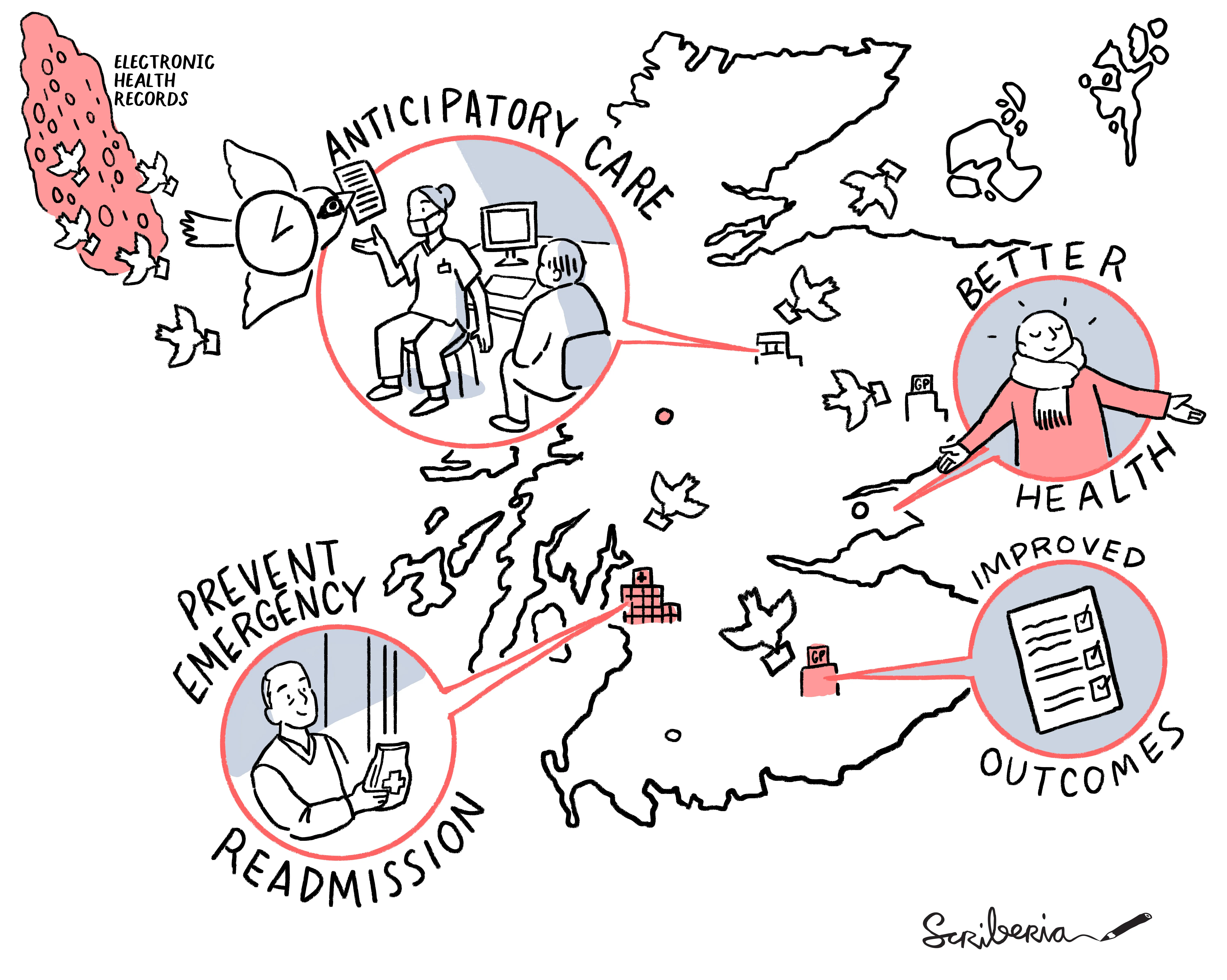
SPARRA version 4 (SPARRAv4) is the latest version of the SPARRA model, developed by our team in collaboration with PHS. Supported by The Alan Turing Institute and Health Data Research UK, the project was co-led by Dr Catalina Vallejos and Prof Louis Aslett (Durham).
Similar to its predecessors, SPARRAv4 inputs include demographic data (such as the Scottish Index of Multiple Deprivation) together information that is routinely collected by healthcare providers (such as patient history, prescription details and previous hospital admissions).
A key difference with respect to earlier versions is the underlying modelling approach. SPARRAv4 uses a topic model to extract more granular information from prescriptions and diagnostic data. Furthermore, it uses an ensemble of machine learning models (including boosted decision trees and neural networks) to capture more complex data patterns.
Trained on electronic health records from 4.8 million residents between 2013 and 2018, our updated model provides improved predictive performance than SPARRAv3. Our analysis also gives insights into the epidemiology of emergency admissions in Scotland; for example, types of admissions (as defined by the recorded primary diagnosis) that are harder to predict.
Throughout model development, our team placed high emphasis on transparency and reproducibility while ensuring compliance with data governance constraints. This includes the use of TRIPOD reporting guidelines and open-source code.
SPARRAv4 will be soon deployed by PHS across Scotland, replacing SPARRAv3.
- Paper: Liley et al (2024), npj Digital Medicine.
- Code: Publicly available in GitHub.
- Press release: AI tool predicts emergency hospital risk .
Stratified performance of SPARRA
We carried out a retrospective analysis to comprehensively evaluate how SPARRA (versions 3 and 4) performs across population subgroups defined by age, sex, ethnicity, socioeconomic deprivation, and geographic location (rural vs urban, island vs mainland residence).
We considered differences in overall predictive performance (including discrimination and calibration) and score distribution, using causal methods to identify effects mediated through age, sex, and deprivation.
Our online dashboard enables researchers, practitioners and members of the public to explore these results interactively.
In addition to The Alan Turing Institute and Health Data Research UK, this work was also supported by The Health Foundation as part of the Data-Driven Systems and Health Inequalities programme.
- Paper: Thoma et al (2024), PLoS Digital Health .
- Code: Publicly available in GitHub.
- Online dashboard: Available in PHS website.
- R package: Available in CRAN.
Related work inspired by SPARRA
Beyond work directly related to the development and evaluation of SPARRA, our team has also developed methodological and ethical challenges related to the use and updating of SPARRA and similar risk prediction models.
Model updating after interventions
Machine learning is increasingly being used to generate prediction models that inform interventions in real-world settings; for example, anticipatory care plans informed by SPARRA. In parallel, there is increasing interest in updating and improving such models over time, as more data becomes available and modelling techniques improve: interventions informed by a risk score can alter the outcome they were trying to predict, leading to a feedback loop that is often referred to as ‘performative prediction’.
We demonstrate the consequences of ‘naive updating’, where performative prediction is not accounted for when updating a model, and this is done repeatedly over time. We also discuss potential routes to overcome these issues.
- Paper: Liley et al (2021), AISTATS.
- Code: Publicly available in GitHub.
Ethical considerations of use of hold-out sets in model updating
We explore the potential use of ‘hold-out sets’, in which a set of patients do not receive model derived risk scores, as a potential solution to address performative effects in the context of model updating.
We present an overview of clinical and research ethics in this context, focusing on the ethical principles of beneficence, non-maleficence, autonomy and justice. We also consider informed consent and the principle of clinical equipoise, and present illustrative cases of potential hold-out set implementations.
Adaptive model updating using a simulated environment
We consider the general challenge of model updating in the presence of concept drift, where the underlying distribution of the data changes over time. We review existing strategies, including regular model updates (e.g. yearly) as well as those triggered by concept drift detection.
We present a novel strategy, AMUSE (adaptive model updating using a simulated environment) to balance the costs and benefits associated to model updating. Our key idea is to use a simulated training environment in which possible episodes of drift are simulated by a parametric model. A reinforcement learning is then used to learn an optimal updating strategy.
- Pre-print: Chislet et al (2024), arXiv.
Group members
Current and former group members that have contributed to this project:
- Dr Catalina Vallejos (group leader)
- Dr James Liley (former PDRA)
- Dr Ioanna Thoma (former PDRA)
- Louis Chislett (PhD student)